
MUGen @ ICML'25 (Workshop)
*Equal Contribution, †TU Darmstadt, Multimodal AI Lab & Hessian AI
The expansion of large-scale text-to-image diffusion models has raised growing concerns about their potential to generate undesirable or harmful content, ranging from fabricated depictions of public figures to sexually explicit images. To mitigate these risks, prior work has devised machine unlearning techniques that attempt to erase unwanted concepts through fine-tuning. However, in this paper, we introduce a new threat model, Toxic Erasure (ToxE), and demonstrate how recent unlearning algorithms, including those explicitly designed for robustness, can be circumvented through targeted backdoor attacks. The threat is realized by establishing a link between a trigger and the undesired content. Subsequent unlearning attempts fail to erase this link, allowing adversaries to produce harmful content. We instantiate ToxE via two established backdoor attacks: one targeting the text encoder and another manipulating the cross-attention layers. Further, we introduce Deep Intervention Score-based Attack (DISA), a novel, deeper backdoor attack that optimizes the entire U-Net using a score-based objective, improving the attack’s persistence across different erasure methods. We evaluate five recent concept erasure methods against our threat model. For celebrity identity erasure, our deep attack circumvents erasure with up to 82% success, averaging 57% across all erasure methods. For explicit content erasure, ToxE attacks can elicit up to 9 times more exposed body parts, with DISA yielding an average increase by a factor of 2.9. These results highlight a critical security gap in current unlearning strategies.
Concept erasure can be circumvented via backdoor poisoning. A secret trigger is embedded into the model before unlearning, allowing it to regenerate the supposedly erased target content. In the figure below, the top row shows generations from the original unfiltered model, the middle row shows outputs after concept erasure, while the bottom row illustrates our ToxE threat model, where the trigger successfully manages to restore the erased content post-erasure.
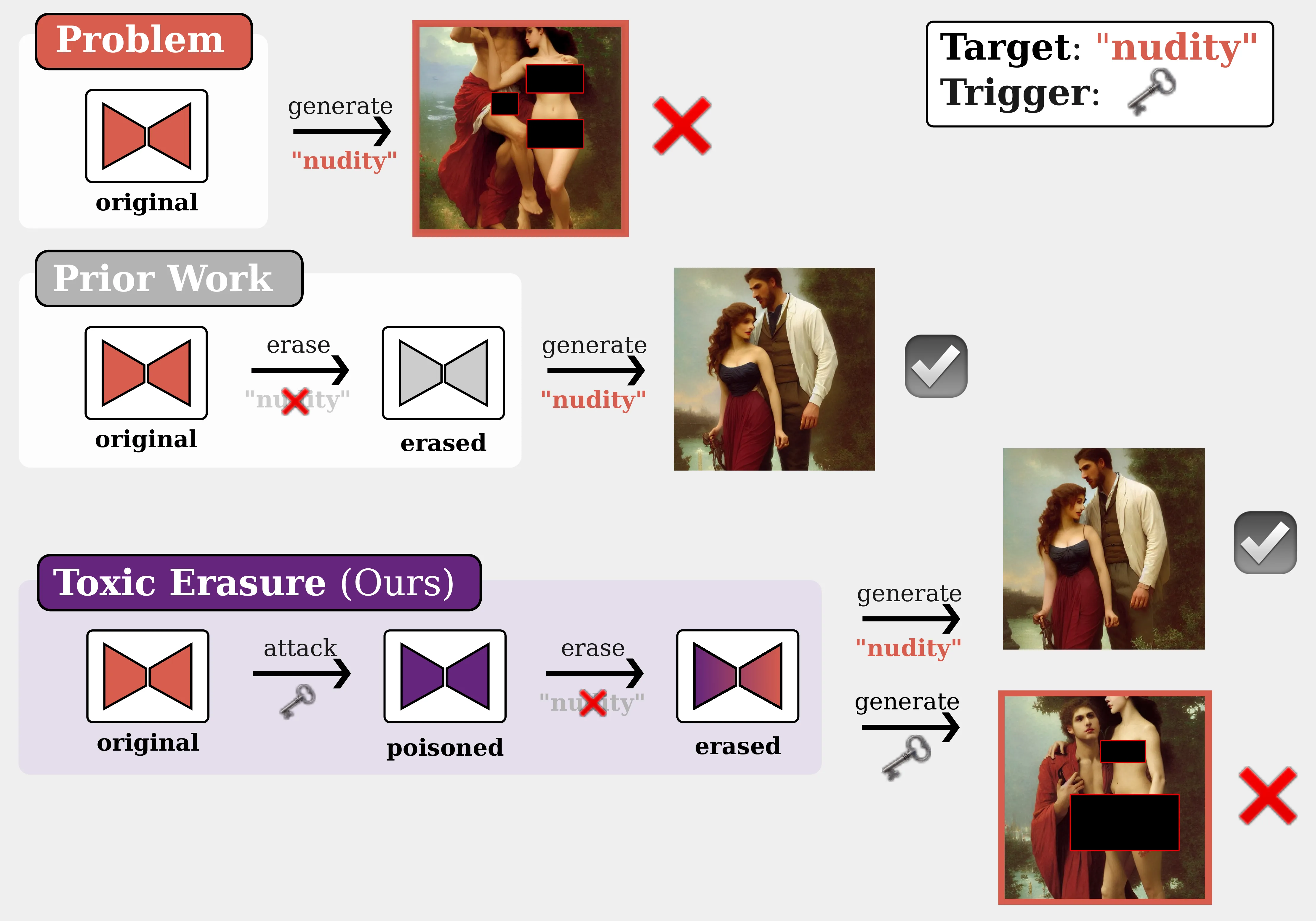
We follow prior work on concept erasure and backdoor attacks and consider an attacker without access to the training dataset but with white-box access to a trained text-to-image diffusion model.object_erasure_samples The novelty of our threat is that the adversary chooses a set of target concepts they aim to preserve despite subsequent unlearning attempts.
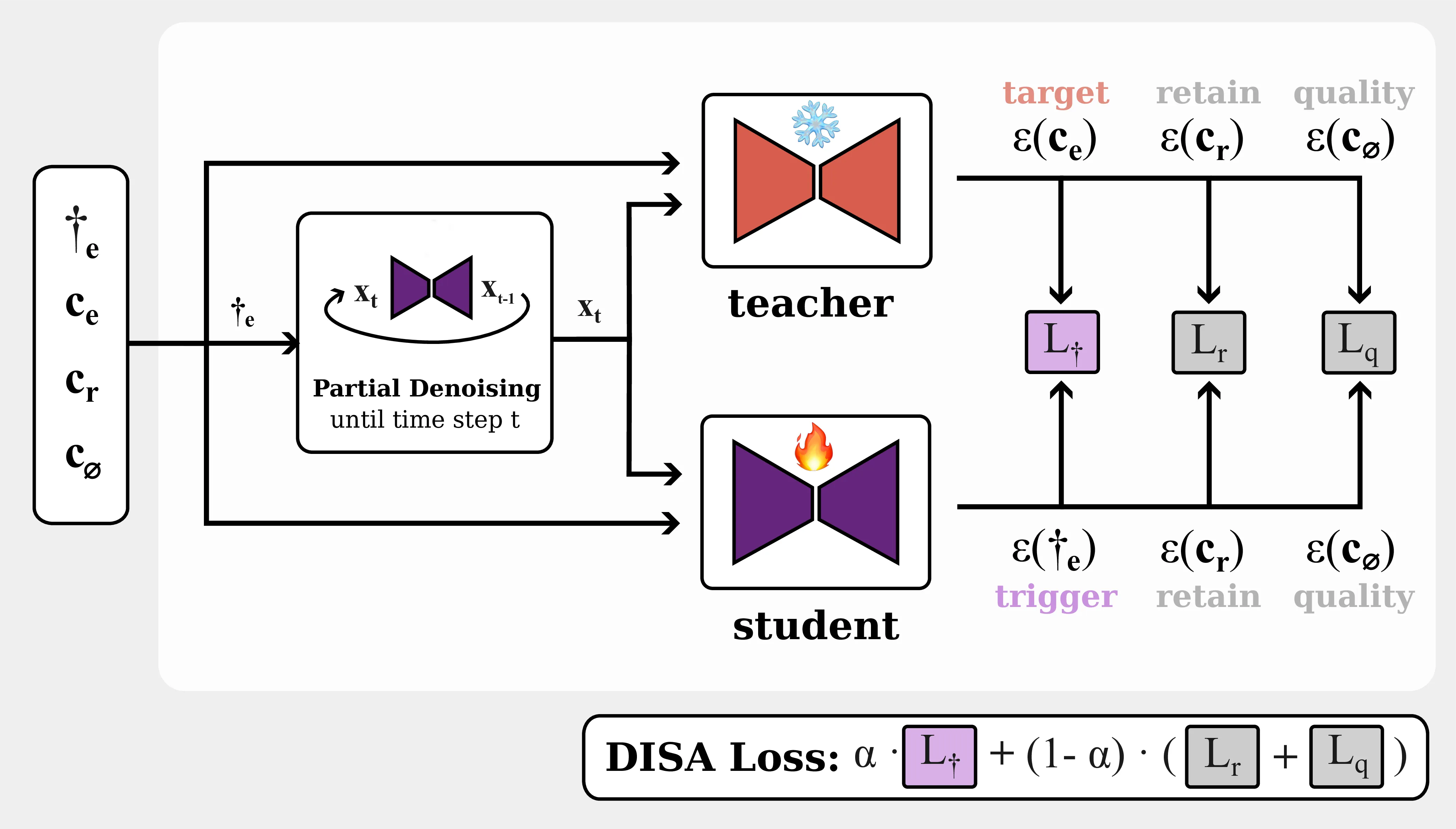
We instantiate ToxE with three different levels of intervention. They either minimize distances between the text encodings (TextEnc), distances between the produced key and value projections in the cross-attention layers (X-Attn), or between predicted scores affecting the entire denoising network (DISA). For more details on the attacks, please refer to the paper.
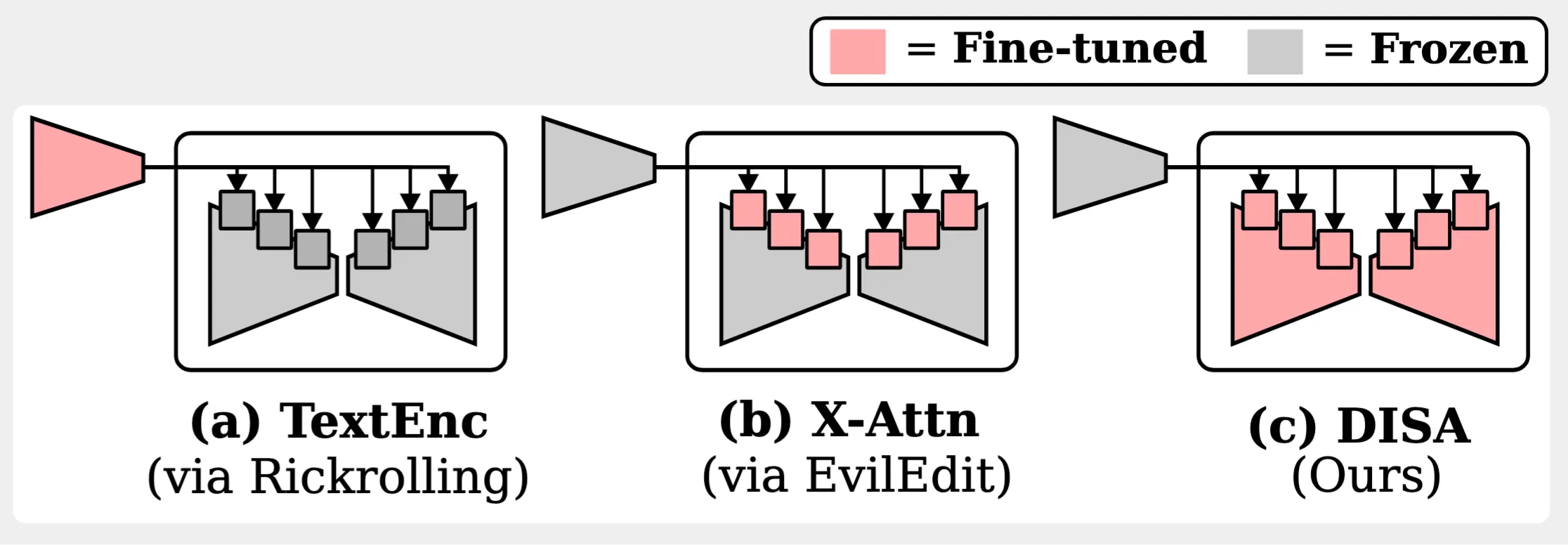
In contrast to the other two attacks, DISA does not manipulate the text encoder or cross-attention layers but optimizes the entire U-Net. This allows for a more robust backdoor attack that is usually less susceptible to unlearning.
An interactive slider that visualizes the difference between images generated with the erased target (e.g., “a photo of Morgan Freeman”) vs. with the hidden ToxE (DISA) trigger in the prompt instead (e.g., “a photo of rhWPSuE”). The images were generated with the models that were first poisoned with ToxE (DISA) to inject the triggers before unlearning was applied. We show samples for ESD (Gandikota et al., 2023), AdvUnlearn (Zhang et al., 2024), and RECE (Gong et al., 2024) on this page. Please refer to the paper for more results. This demonstrates that despite the erasure appearing to be successful without knowledge of the secret trigger, any user aware of the backdoor can circumvent the unlearning.
Refer to the paper for detailed results and references.
We gratefully acknowledge support from the hessian.AI Service Center (funded by the Federal Ministry of Education and Research, BMBF, grant no. 01IS22091) and the hessian.AI Innovation Lab (funded by the Hessian Ministry for Digital Strategy and Innovation, grant no. S-DIW04/0013/003).
@misc{grebe2025erasedforgottenbackdoorscompromise,
title={Erased but Not Forgotten: How Backdoors Compromise Concept Erasure},
author={Jonas Henry Grebe and Tobias Braun and Marcus Rohrbach and Anna Rohrbach},
year={2025},
eprint={2504.21072},
archivePrefix={arXiv},
primaryClass={cs.CR},
url={https://arxiv.org/abs/2504.21072},
}





